Imagine designing a new part of the application for a business that is not well defined yet. After a few knowledge-crushing sessions, you see the boundaries of the new model and start to know how the business is running and decide to go DDD way. Together with the team, you are making proof of concept of the application, but you are also making a conscious decision to take a technical debt, just to hasten development. After a few sprints, it appears that precious PoC became a production-working application that nobody wants to work with because of tests complexity and deployment problems. You are facing a time when you need to refactor your application and pay off the debt you took.
What we will cover here
We will walk through steps performed on real, production running application. Those steps allowed to separate Read Models into an independent application. As a result, data processing and deployment times will decrease, the coupling between modules will be reduced and development will become easier. This article will not explain what is Read Model or what is the difference between mentioned architecture styles.
Starting a new area of business
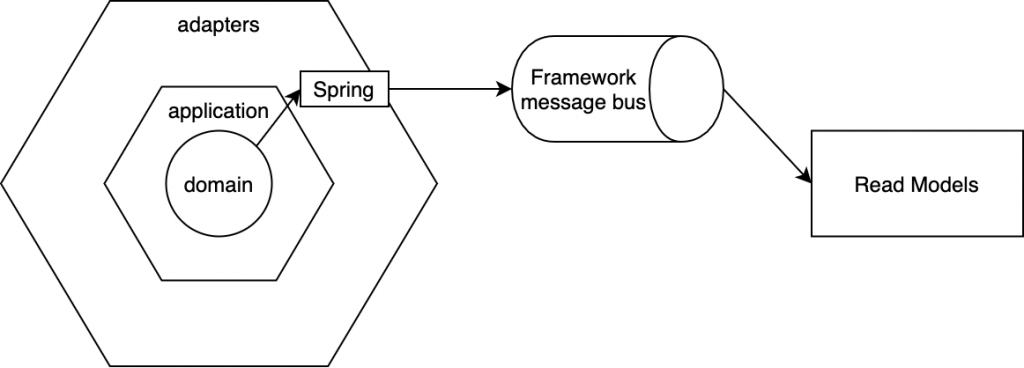
As a team, we were well prepared to design our application. As it was business-critical, we decided to use hexagonal architecture, although we pushed it to a state, that it became hard to maintain.
During development, we were mostly focused on the Core Domain, as it is important for the business to earn money. It was natural to pay more attention to cash flows processes through the company than generating reports — in the end, they can always be generated once more, but when you lost money due to invalid flow, your company is losing financial liquidity.
How did we let our application degenerate?
The Core Domain of application and Read Models were sharing the same codebase. They were separated with proper packaging and integrated with events. Clear split with events gives an opportunity for spending more time on understanding the business. To limit work related to infrastructure, we decided to use event handling provided by the framework that was used for development.

Its biggest drawback was synchronous processing, but we accepted that at this point. Later, it became a bottleneck, as total processing time of event received by the application was counted in seconds. Tests were getting tangled, making the whole solution hard to test.
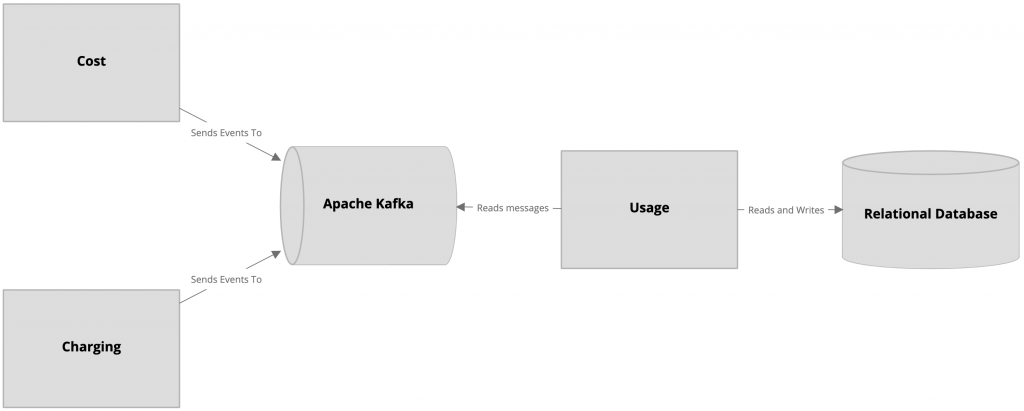
After stabilizing the domain, we started to focus on the Read Models. The solution used to feed them with data has drawbacks, so we made a decision to switch it to Apache Kafka. Unfortunately, there was no time to change already existing solution for a new one, so we started to send events on both channels. Utilising both channels preserved the history of events stored on Kafka — it gives us a possibility for switching off framework broker in the future.

The final version of the domain is pretty lightweight, but reporting is not. They have to process data produced by the application, merge them with data from other services and provide it to customers. There was still one more thing — this whole domain, application, adapters and Read Models were a modular monolith, deployed all together is single deployment package.
We used DDD, what was wrong?
Service was working, but it became heavy. Problems started to pile up, making development more and more difficult.
- Processing of single event by domain took seconds. We did not have a requirement on performance, but clearly it was not what we should aim for. The root problem, in this case, is synchronous processing of a few types of events emitted by domain.
- Application startup was too long. It was so long that deployment pipelines had to use extended timeouts for application node startup. There were two reasons for this: read model database migration affecting the deployment time of application, and the amount of data pre-loaded by the Read Models.
- Automated testing became harder and harder. Flow, potential ways of data processing and the number of cases increased since we wrote our first test. In addition, some use cases were still using synchronous processing, coupling code even more.
Steps to move forward
To solve all problems that we had, we had to clearly define, what we want to achieve, and how we want to do it. After defining the responsibilities for specific modules, defined the desired state as following:
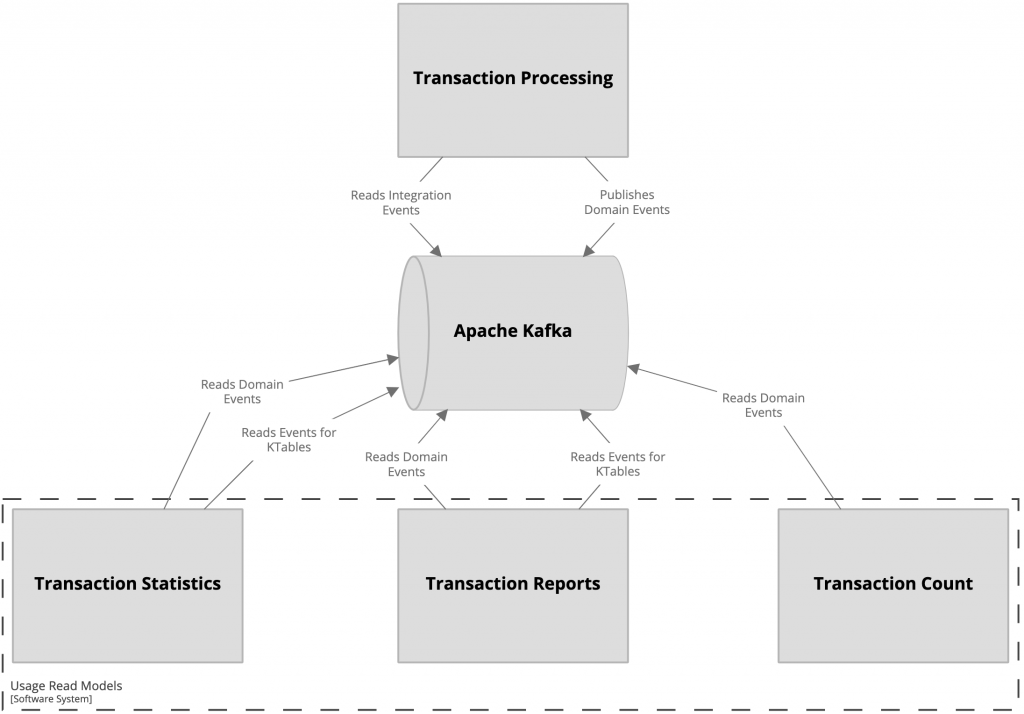
Whole processing has to be done asynchronously, with a separate deployment unit that will contain only Read Models. This required from us some planning, and we prepared the following plan.
Step one: tests review
The base for every refactoring should be a guarantee that the application provides the same functionality after it is changed. Having a Test Driven Development approach placed us already in a good starting position. While reviewing tests, you should pay more attention to the integration ones over unit tests. In this case, it is more important to keep usage scenarios the same from a user perspective than catch up on missing class-based tests.
Fortunately, in our case Core Domain tests were just fine — they covered all business cases. On the other hand, Read Models were missing the whole event processing part. Tests were assuming that data is already in the database, and just checked if they are served in a proper way.

It may look trivial, but actually, data conversion and applying events is crucial for Read Models. It is basically their responsibility — convert the actual state to the representation needed by consumers. As we were switching from framework-provided event handling to the Apache Kafka, we started to write missing tests with Testcontainers that will allow us to easily change the message broker. This leads us to the next step, which is:
Step two: if possible, process data asynchronously
One of the biggest problems of service was data processing time. Still, it was sufficient to meet our performance needs, but with every added feature time increased. Scaling out the service would be a short-term solution in case of higher performance need, but it causes higher utilisation of infrastructure. That would lead to scaling it up, significantly increasing operating cost.
From the business perspective, it was totally fine to see processed data after a few seconds, so asynchronous processing was more than advised. Emitting events created by domain, expressing a fact that something already happened, is enforcing this approach. You should aim for event-based communication and allow other modules of application to take action on them.
If you are already emitting events, but you are doing it synchronously and you are unable to migrate fully into asynchronous processing, it is perfectly fine to have two message channels. One for legacy code, that cannot be changed right now, second, asynchronous, for migrated modules. In future, when you will migrate all synchronous modules, an old, unused message channel can be removed.
In our case, having an architecture that follows the event-driven approach simplified our work on asynchronous processing. After adjusting tests to expect that data was transferred through Apache Kafka, we only needed to add a code for publishing them and reconfigure event listeners.
Step three: make code independent
At this point, code should be well tested. Decent coverage of user scenarios allows changing code with the confidence of not breaking functionality. Making modules independent from each other will be probably the hardest part of splitting the codebase. We are using packages to organize code depending on its purpose.
It is good to start with the creation of readmodel package in your code, and trying to move there all related code. Later, you will need to do one of the most boring work: find dependencies from other packages into readmodel. This is absolutely crucial, that domain and application to not be dependent on the form of data presentation. When you will finish it, you will need to do second most boring, but important task: find dependencies in another way around. readmodel itself should not have dependencies of outside its package.
The only thing, that could be shared by all packages, are domain events, as long as they are stored in a dedicated package. While reviewing your packages, you might get into the point, that some copying of code will be needed. Do not worry about breaking DRY principle, just think about readmodel like about an application that is totally separate from the rest — it is just sharing the code repository.
Step four: carve out the Read Models
When you are deciding to carve out Read Models into microservices, you should be prepared to do microservices first. If this is going to be your first microservice, you will need a lot of research and Ops work to make it happen. Hopefully, you already are familiar with pipelines and monitoring, so you can just walk through check points:
- prepare new source code repository for extracted part of the application and move code there
- set up pipelines for new microservice
- create the required infrastructure (databases, servers, namespaces, everything that your application may need)
- attach monitoring of new service, and review rules for old one (e.g. check if there are rules that are using migrated read model API)
- notify consumers about new API address
- finally, remove old, unused Read Models from the Core
Before deploying new applications, make a plan for data migration. Think about what you can read from existing events, and what you will need to migrate from the database itself. Keeping data consistent can be a real tricky, so try to challenge your plan with analysing all possible ways of doing it.

When you checked everything from the list, you can start deploying new Read Model. Let the data migrate, and for some time keep both versions of application running — old, not split application, and a new one. It will allow you to compare data and check if everything is correct. It will also allow API consumers to switch to a new version of it.
The last step is a pure pleasure — remove all, Read Model related code from your Core application. If you did everything correctly, you will be able to select a readmodel package and simply hit the delete button.
Summary
Complexity of carving out Read Models from your application depends strongly on your architecture choices. With a modular monolith, it might be a fairly easy task to do, but if you are working with legacy code without a clear split, it will require long hours of analysing before you will even start.
Think about it when you are starting a new project. PoC can be done with respecting agile, architecture can be kept clean, and tests that are checking contracts can be written from the very beginning. Nevertheless, at some point in time, you will need to reorganize your project, or you will end up with a monster project that you will chase you in nightmares. This is the investment, that will pay back with easier development and robust application.
Featured photo by Dominik Scythe on Unsplash.